从这一节开始就进入传输层的部分了,也是内容最丰富可能更贴近于实际的部分了,很多书籍会从TCP开始介绍传输层,我觉得学习应该从简单的到难的,所以我选择从UDP先开始,况且是现有UDP协议并且发展至成熟然后再有的TCP。
UDP协议历史
如果有人问我他想阅读RFC,也就是我前面提过的互联网的标准,有啥推荐的着手点。标准这种玩意儿大部分都又枯燥又长,真要看,睡着了是必须的,不看吧,总感觉与人谈论的时候少了一种老子当年也是参加过啥啥的感觉。所以如果真想看看RFC到底都写些啥,怎么写,我十分推荐原始的UDP标准作为一个开始,UDP的RFC号是768,一共就3页,完整而又严谨的阐述了UDP协议,虽然是英文,全看一遍也就最多30分钟吧,而且有图有真相,有文字有引用,作为一个着手点再合适不过。
UDP协议,学名User Datagram Protocol,Datagram这个名词第一次在网络中是在1970年,在一个很早期的网路设计CYCLADES中被一个叫Louis Pouzin提出。这个词是data和telegram的一个组合,而这个CYCLADES是一个保证在可靠传输data而不保证可靠传输网络的设计,简单的来说就是这个网络设计保证从放到一个端口上传出去的数据可以完整无误的到达另一端但是不保证一端想要传输的数据都能可靠的被放在端口上或者被另一端取出。这个Louis Pouzin提出这样一个想法的原因之一就是他并不喜欢事情搞得很复杂,他认为没有必要在一个已经具有可靠传输的机制上再叠加一层可靠传输的端到端的设计。
从目前看这个想法虽然是有弊端的,但是在当时并没有那么大的网络负载和网络架构的时候,这是一种经济而又行之有效的办法,所以Datagram这个想法就被IP协议的设计者们所借鉴。
UDP特点
就如上一节所描述,Datagram提供的是一种不可靠的协议传输,最简单的不可靠就是从A端的传输层发出的数据包不保证B端能接收到,或者按需要收到,B端也无需向A端表明自己是否收到。这有点像以前有一种群寄广告的方法,寄广告的一方并不知道他寄出的地址的人有没有收到自己寄出去的广告,而收到广告更没必要向寄出的人表明自己收到与否。
本质上为什么称UDP为不可靠呢?因为他并不会保存发送出去的备份,这个特点在UDP中导致会有以下几个方面的表现:
- 不能保证传送出去的数据包不丢失,不重复
- 不能保证传送出去的一系列数据包在接收端还是以相同的顺序被读取
- 不能保证传送出去的数据包不出错
另外UDP也没有拥塞控制,这个专业名词到TCP的时候会详细描述,其实就是当路上流量很大甚至被堵的完全走不动的时候,UDP协议会不管这些东西,继续向网络上发送数据包。这样会引起很多不良后果,比如丢包,造成网络整个的崩溃。
那么UDP有这么多弱点为什么还作为传输层两巨头之一被广泛运用呢?因为其长处也很明显,就是经济。所谓经济就是UDP没有复杂的建立连接,重传重排,拥塞避免(这些名词后面都会成为主角)等等,他只管在一端把数据发出去,同等情况下相对于要做这么多额外工作的协议肯定要快一些且“经济”一些,那么有的应用对于数据包短暂丢失,乱序,错乱都是能够忍受的。最能理解的应用应该是网络视频,网络电话之类的,对于一两帧的丢失并不会引起用户的抱怨。当然除了视频,还有很多协议是建立在UDP之上的,他们中有的已经退出历史舞台,有的依然天天都会为我们的上网默默的做出你看不到的工作,比如DHCP,DNS。甚至还有由于其没有连接性的特点不得不使用UDP的场景,就是传输层广播。
UDP数据包头
UDP是工作在IP之上的,是一个应用层到IP的简单接口,所以UDP整个的数据包是放在IP data部分的(可以回去再复习一下IP数据包头格式)。而UDP数据包头被设计的及其简单而又有效,整个包头只有8个字节,分为四个部分。这里我要用RFC里面的原图了,这里我不得不说RFC里的图是我最佩服的部分之一,各种各样的图示都用字符来绘画出来,有的真的可以说让我叹为观止。
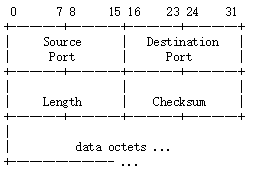
从低字节到高字节依次是源端口,目的地端口,数据包长度,CRC校验和。
如果让我选传输层第一关键词,我会选端口,应用层的各种协议的最重要的标识物之一就是传输层的端口。为什么在IP地址上还要加上端口这个概念呢?第一个作用是可以让一个主机上的应用层可以有标识进行IP地址的复用,第二个就是分层思想里最重要的,每一层都处理每一层的事情,链路层看到MAC地址就知道这是链路层的数据包,网络层看到IP地址或者类似的地址就知道自己该干活了,传输层也是一个道理。这样数据才能沿协议栈不断的上传,而每一层也可以干自己的事情。
所以类似IP数据包头有自己和对端的IP地址一样,在UDP数据包头中会含有自己的源端口号和对方的端口号。不过由于UDP是不需要对方返回响应消息的,所以源端口号可以填0表示不填。一个端口号是16位,所以一个IP地址最大的端口号是65535,但是很多端口号都是预先被保留用做特定的用途,这个在传输层杂项中我再稍微详细的介绍一下。
接下来按照我前面所介绍的记这种数据头格式的重要部分,就是长度,因为你需要让对方知道我该读多少的数据。
接下来的CRC校验和比较有趣了,IP包头的效验和是头部校验和,只有头部的数据会参与计算。而在UDP里,这个校验和采用了一个伪头部的概念。所谓伪头部就是UDP在计算效验和的时会把IP头部的一些信息加入计算,具体的就是如下的信息:

其中包括,源IP地址,目的地IP地址,填充的8位0,协议名(UDP),UDP报文长度,为什么要这么做呢,标准里的解释是通过IP地址可以确认该数据包是不是发送给本机,通过协议,可以确认有没有误传。这样做的好处是很明显的,一是可以再一次确认关键字段没有错误,而是使用伪首部而不是真正的把这些数据放在UDP数据包里可以减少负担。
但是这个设计违背们一直强调的分层思想,在传输层不应该混入网络层的东西,而且在网络层的头数据包CRC中已经让两个IP地址参与计算过了,这里再进行一次校验,看起来有点多余。而我对这个问题也一直不知道最深的设计原理是什么,我的理解是可能在分层思想的时候隐含着虽然每一层都做自己的事情,但是上一层不应该天然相信下一层,在需要的时候他也可以对下一层的某些关键信息再做双层确认。
对于这个校验和,因为UDP是不保证可靠性的,在IPv4中是可以不填的,而以我遇到过的例子来看,大部分是不填的,或者填了对端也不会检验的,所谓多一事不如少一事的哲学思维看来也是通用的。
UDP数据实例
按照风格,再一次让我们来看看现实抓包中的UDP数据包头是什么样子的。
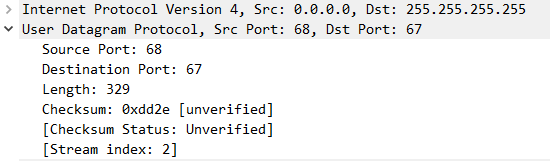
这个图中可以看到,UDP是建立在IP纸上的,这里的源端口号是68,目的地端口号是67,长度329,这里开启了checksum但是对端也不会确认计算的。最后一个stream index 是wireshark内部的编号,用来标识UDP,TCP数据流的序号,用中括号括起来的都不是UDP数据包中真正的内容。
好了,UDP就是这么简单的一个协议,但是用处却是很广泛,从下一节开始,就从不同的几个方面来介绍下UDP在每一台电脑上都会做的几件事情。